1、为什么分区
Kafka 的消息组织方式实际上是三级结构:主题 - 分区 - 消息,主题下的每条消息只会保存在某一个分区中。
Kafka 的三级结构:
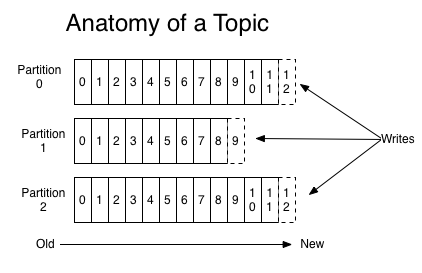
分区是为了实现系统的高伸缩性(Scalability),可以通过添加新的节点来增加整体系统的吞吐量。
2、分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法。
1、自定义分区策略
你需要显式地配置生产者端的参数 partitioner.class,在编写生产者程序时,你可以编写一个具体的类实现 org.apache.kafka.clients.producer.Partitioner 接口,实现 partition() 和 close() 接口。
方法签名:
| |
2、轮询策略
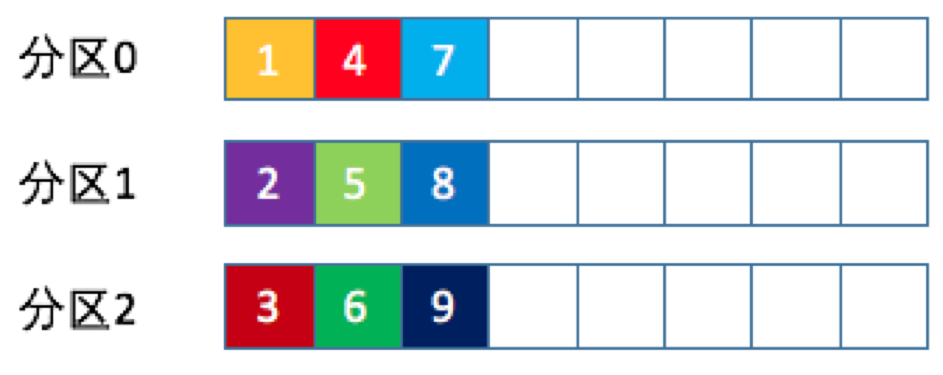
Kafka 默认的分区策略就是轮询策略,轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上。
3、随机策略
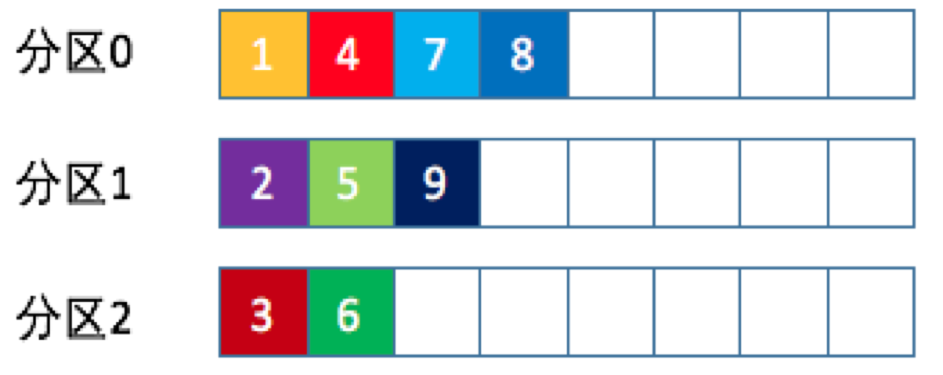
要实现随机策略版的 partition 方法(自定义分区策略),如下:
| |
4、按消息键保序策略
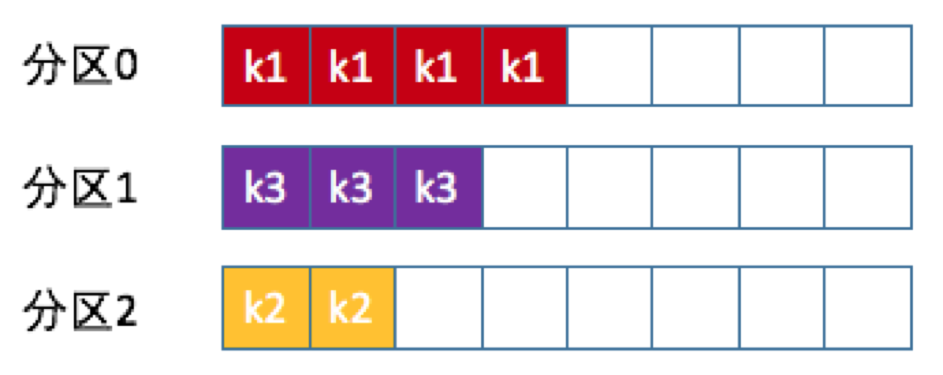
实现这个策略的 partition 方法(自定义分区策略),如下:
| |
Kafka 默认分区策略实际上同时实现了两种策略:如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略。
5、其他分区策略
比较常见的一种就是基于地理位置的分区策略。
比如根据 Broker 所在的 IP 地址实现定制化的分区策略,如下:
| |
我们可以从所有分区中找出那些 Leader 副本在南方的所有分区,然后随机挑选一个进行消息发送。