1、事务隔离级别
事务的 ACID 中的 I 指的就是隔离性(Isolation)。
1、隔离级别
读未提交(read-uncommitted):一个事务还没提交时,它做的变更就能被别的事务看到。
读提交(read-committed):一个事务提交之后,它做的变更才会被其他事务看到。
可重复读(repeatable-read):一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。
串行化(serializable):当出现读写锁冲突的时候,后执行事务必须等前一个事务执行完成,才能继续执行。
MySQL 的隔离级别设置为"读提交"。
2、事务隔离例子
| |

在不同的隔离级别下的结果:
隔离级别为读未提交,v1 = 2, v2 = 2, v3 = 2。
隔离级别为读提交,v1 = 1, v2 = 2, v3 = 2。
隔离级别为可重复读,v1 = 1, v2 = 1, v3 = 2。
隔离级别为串行化,v1 = 1, v2 = 1, v3 = 2。
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。
在可重复读隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。
在读提交隔离级别下,这个视图是在每个SQL语句开始执行的时候创建的。
在读未提交隔离级别下,直接返回记录上的最新值,没有视图概念。
在串行化隔离级别下,直接用加锁的方式来避免并行访问。
3、事务配置方式
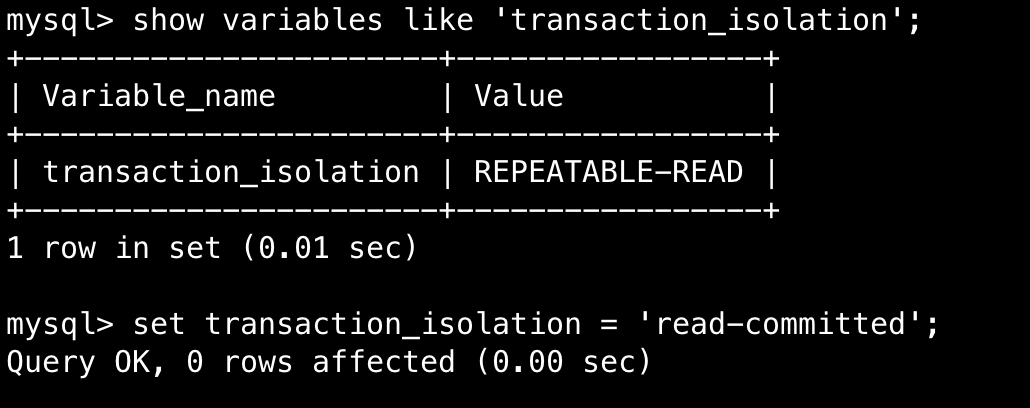
通过命令 show variables like 'transaction_isolation'; 来查看当前隔离级别。通过命令 set transaction_isolation = 'read-committed'; 来设置隔离级别。
2、事务隔离的实现
在 MySQL 中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。
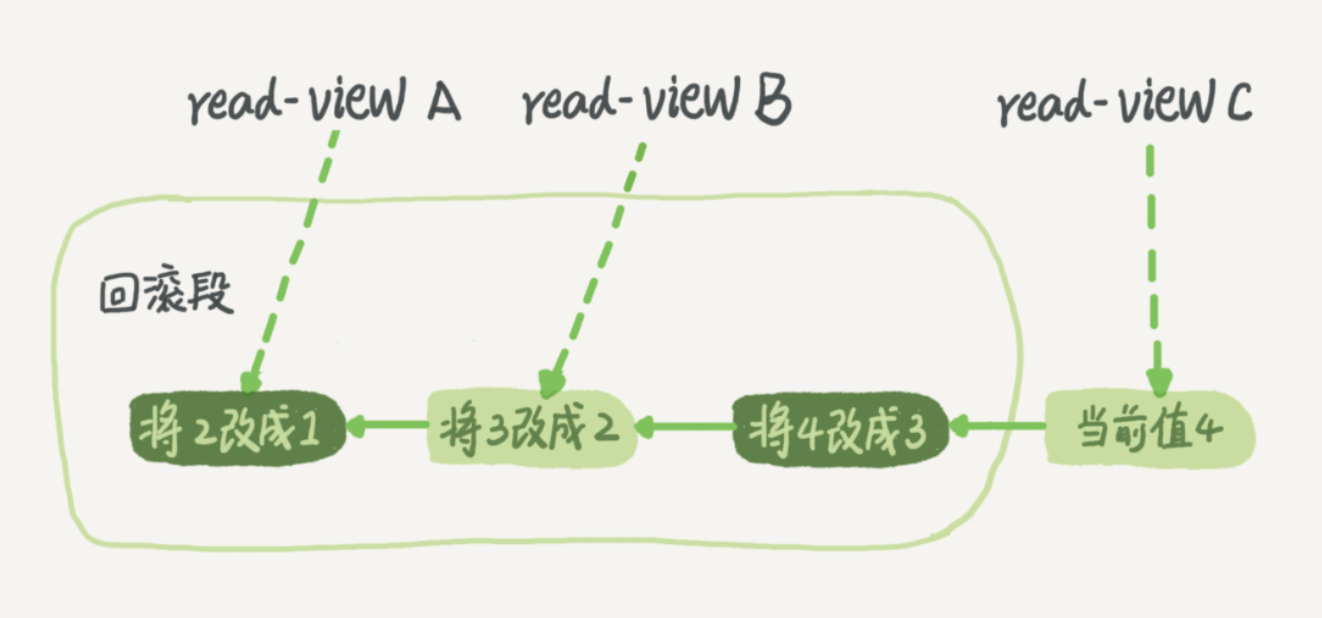
长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。长事务还占用锁资源,也可能拖垮整个库。
3、事务的启动方式
建议你总是使用 set autocommit = 1, 通过显式语句的方式来启动事务。
在 autocommit = 1 的情况下,用 begin 显式启动的事务,如果执行 commit 则提交事务。如果执行 commit work and chain,则是提交事务并自动启动下一个事务。
你可以在 information_schema 库的 innodb_trx 这个表中查询长事务,比如下面这个语句,用于查找持续时间超过 60s 的事务。
| |
4、问题
怎样避免长事务?
在开发端:
- 设置
set autocommit = 0。 - 确认是否有不必要的只读事务。
- 通过
SET MAX_EXECUTION_TIME命令,来控制每个语句执行的最长时间,避免单个语句意外执行太长时间。
在数据库端:
- 控 information_schema.Innodb_trx 表,设置长事务阈值,超过就报警/或者 kill。
- ercona 的 pt-kill 这个工具不错,推荐使用。
- 在业务功能测试阶段要求输出所有的 general_log,分析日志行为提前发现问题。
- 如果使用的是MySQL 5.6或者更新版本,把 innodb_undo_tablespaces 设置成2(或更大的值)。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。