1、索引的常见模型
1、哈希表
以键-值(key-value)存储数据的结构。只适用于等值查询的场景。
2、有序数组
查询效率高,但更新数据,成本高。只适用静态存储引擎。
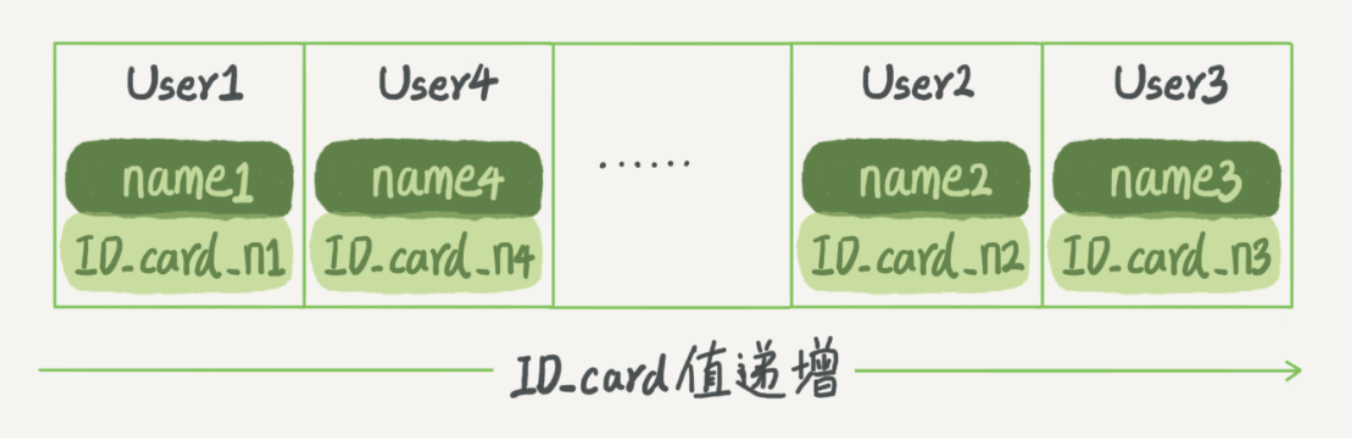
上面数组的按照 ID_card 升序排列,如果查询条件是 where ID_card = '?',可以用二分法查询。
3、搜索树
InnoDB 引擎中使用 B+ 树( N 叉树)。可以减少磁盘 IO。
2、InnoDB的索引模型
我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引,建表语句如下:
| |
表中 R1 ~ R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6)。
在 InnoDB 引擎中,每个索引就是一颗 B+ 树。两颗索引树如下。
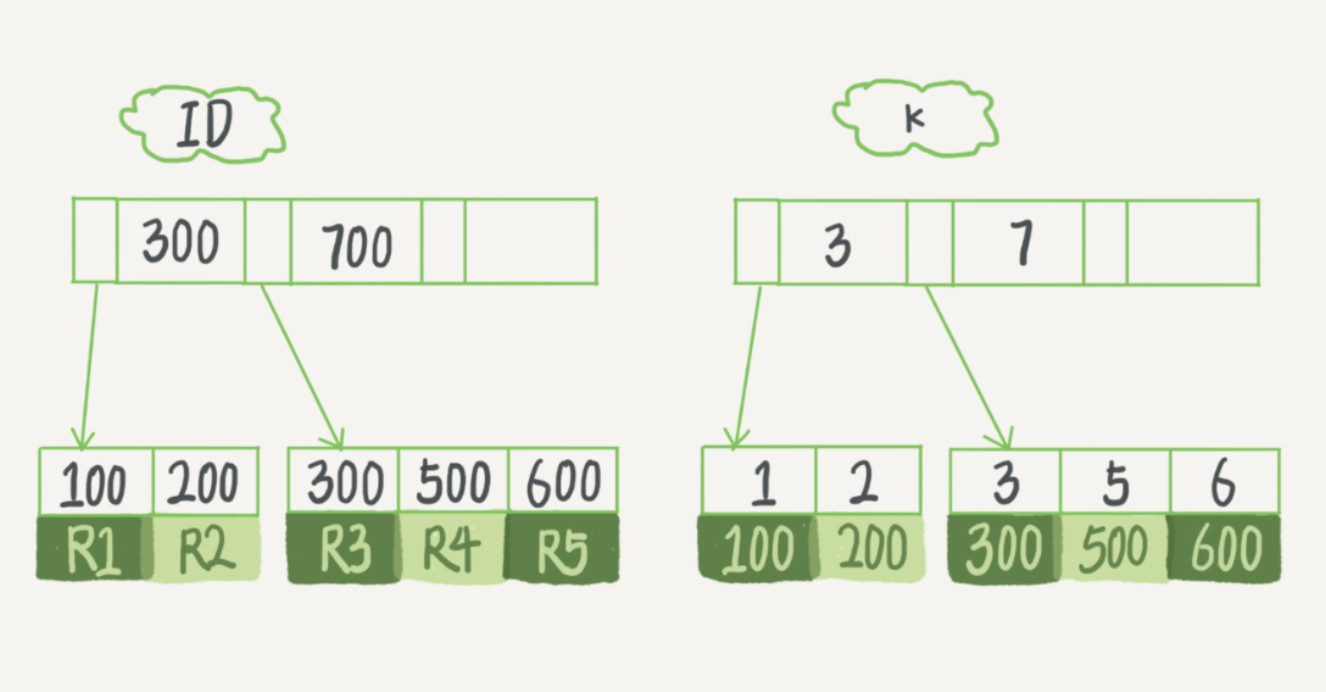
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 主键索引的叶子节点存放的是整行数据。
- 非主键索引的叶子节点存放的是主键的值。
基于主键索引和普通索引的查询有什么区别?
- 如果语句是
select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵B+树; - 如果语句是
select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
3、索引维护
B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面这个图为例,如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约50%。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。
总结:
如果主键是自增的,每次插入一条新的数据,就是追加操作,就不会触发页分裂。 主键长度越小,普通索引的叶子节点就越小,占用的空间也就越小。
4、问题
对于上面例子中的 InnoDB 表 T,如果你要重建索引 k,你的两个 SQL 语句可以这么写:
| |
如果你要重建主键索引,也可以这么写:
| |
可以执行 alter table T engine=InnoDB; 来重建索引。