1、选错索引
一个例子,建表语句如下:
| |
往表 x 中插入 10 万行记录,取值按整数递增,即:(1,1,1),(2,2,2),(3,3,3) 直到(100000,100000,100000),存储过程如下:
| |
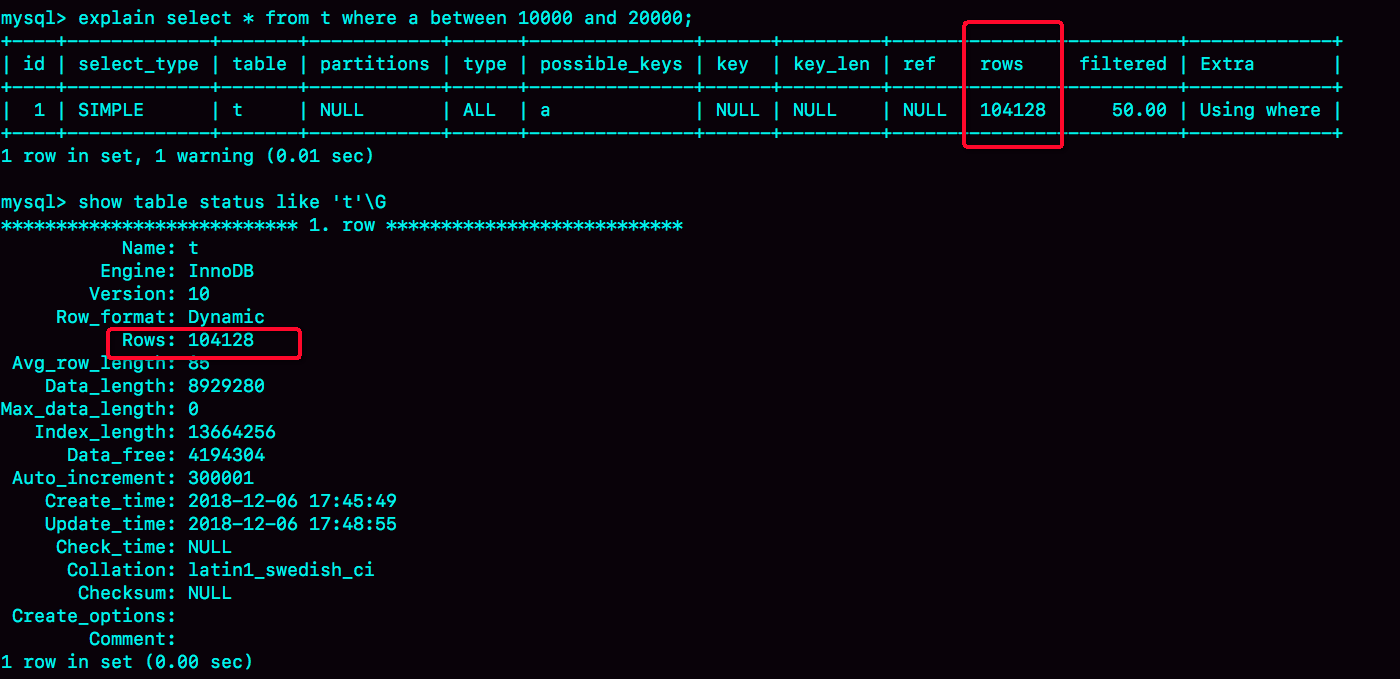
分析一条 SQL 语句 select * from x where a between 10000 and 20000;

我们再做如下操作。

这时候,session B 的查询语句 select * from t where a between 10000 and 20000 就不会再选择索引 a 了。
查看慢查询:
临时开启慢查询:
| |
实验过程就是这三个语句:
| |
这三条 SQL 语句执行完成后的慢查询日志:
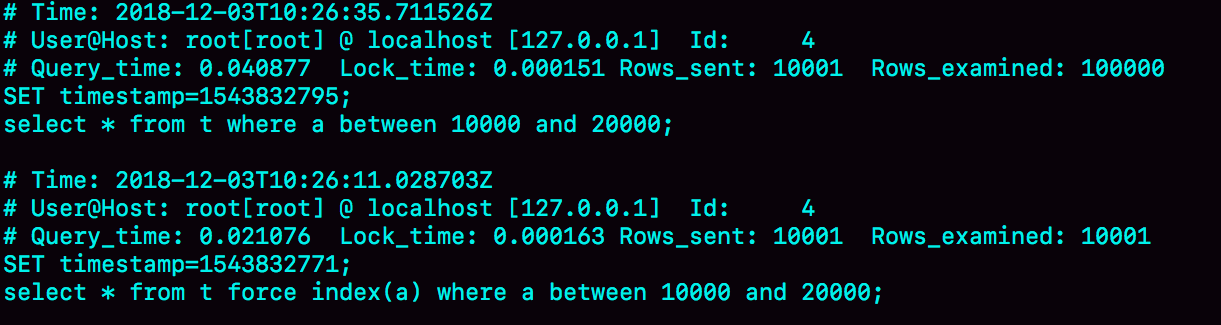
Q1 扫描了 10 万行,显然是走了全表扫描,执行时间是 40 毫秒。Q2 扫描了 10001 行,执行了21毫秒,很显然 mysql 选错了索引。
2、优化器的逻辑
在第一篇文章中,我们就提到过,选择索引是优化器的工作。
优化器选择索引会根据扫描行数、是否使用临时表、是否排序等因素进行综合判断。
当然,这个例子中只有扫描行数这个因素,对于扫描行数,MySQL 根据统计信息来估算记录数,抽样来得到索引的基数信息(区别度),如下图。

采样统计的时候,InnoDB 默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
在 MySQL 中,有两种存储索引统计的方式,可以通过设置参数 innodb_stats_persistent 的值来选择:
- 设置为 on,表示统计信息会持久化存储。这时,默认的 N 是 20,M 是 10。
- 设置为 off,表示统计信息只存储在内存中。这时,默认的 N是 8,M 是 16。
MySQL 选错索引,是因为索引统计信息不准确,修正统计信息,执行 analyze table x; 命令。
另外一个语句:
| |
从条件上看,这个查询没有符合条件的记录,因此会返回空集合。
如果优化器使用索引 a 的话,执行速度明显会快很多,执行 explain命令后:

返回结果中 key 字段显示,这次优化器选择了索引 b。
从这个结果中,你可以得到两个结论:
- 扫描行数的估计值依然不准确。
- 这个例子里 MySQL 又选错了索引。
3、索引选择异常和处理
- 一种方法是,采用
force index强行选择一个索引。 - 另一种方法是,我们可以考虑修改语句,引导 MySQL 使用我们期望的索引。
修改语句后:

之前优化器选择使用索引 b,是因为它认为使用索引 b 可以避免排序( b 本身是索引,已经是有序的了,如果选择索引 b 的话,不需要再做排序,只需要遍历),所以即使扫描行数多,也判定为代价更小。
现在 order by b,a 这种写法,要求按照 b,a 排序,就意味着使用这两个索引都需要排序。因此,扫描行数成了影响决策的主要条件,于是此时优化器选了只需要扫描 1000 行的索引 a。
这种修改并不是通用的优化手段,只是刚好在这个语句里面有 limit 1,order by b limit 1 和 order by b,a limit 1 都会返回b 是最小的那一行,逻辑上一致,才可以这么做。
另一种修改语句:

在这个例子里,我们用 limit 100 让优化器意识到,使用 b 索引代价是很高的。其实是我们根据数据特征诱导了一下优化器,也不具备通用性。
- 第三种方法是,有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
- 第四种方法是,删掉索引 b。
4、问题
前面我们在构造第一个例子的过程中,通过 session A 的配合,让 session B 删除数据后又重新插入了一遍数据,然后就发现 explain 结果中,rows 字段从 10001 变成 37000 多。
而如果没有 session A 的配合,只是单独执行 delete from t 、call idata()、explain 这三句话,会看到 rows 字段其实还是10000左右。
答案:
delete 语句删掉了所有的数据,然后再通过 call idata() 插入了 10 万行数据,看上去是覆盖了原来的 10 万行。
但是,session A 开启了事务并没有提交,所以之前插入的 10 万行数据是不能删除的。这样,之前的数据每一行数据都有两个版本,旧版本是 delete 之前的数据,新版本是标记为 deleted 的数据。
这样,索引 a 上的数据其实就有两份。
表的行数,优化器直接用的是 show table status 的值。